
【Boomi MDH : Master Data Hub】の特徴・使いどころ・使い方をご紹介
弊社がパートナーをやらせていただいているiPaaSソリューションのBoomiのご紹介です。
本記事では前回記事に続いてBoomiのソリューションの一つを紹介したいと思います。今回は『MDH』 (Master Data Hub)を取り上げます。MDHを紹介するにあたり、筆者の取得したBoomi資格『Associate Master Data Hub Certification 2022』の内容も踏まえながら進めていきたいと思います。

*Boomiの各資格はboomiverseというDell Boomi社が提供している無料のオンライントレーニングを通して取得できます。学習コンテンツも豊富で質も高いです。
MDH:Master Data Hubとは?
名前から少し察することができるように、MDHでは企業のもつ複数のサービス・アプリケーションで用いている各データのマスターとなるデータを保持し、必要に応じて接続先サービスのデータもMDHのマスターデータで更新できます。正にデータハブの役割を担っているようなイメージです。
MDHではこのような各サービス・アプリケーションに対してのマスターデータとなる情報を保持し、それらのデータを『Golden Records(GR)』と呼んでいます。Golden Recordsは言わば信頼できる唯一の情報源(= Single Source of Truth)となるわけです。MDHではGRを信頼できる状態に保てるように、各サービスのソースデータとID
で紐付けたり、様々な条件やビジネスルールを加えることによって、重複なくより正確にデータを保持できる機能が備わっています。これら機能については後ほど少し触れたいと思います。
どんなビジネスケースに使えるのか
さて、これまでMDHの概要と特徴を少し紹介してきましたが、このMDHはどんなビジネスの問題を解決し得るのか、その使い所についても触れたいと思います。
例えば以下のような状況は割とあるあるなのではないかと思います。
- セールスチームが営業活動を実施する際に顧客のContact情報をCRM(SalesForce)に入力して管理する。
- ステータスがWON/CLOSEDになったら、社内のDB(MySQL)にContact情報を登録する。
- その後、ポストセールス活動では社内の他のチームが他システム/アプリなどからMySQLに対して顧客情報を参照/更新していく一方で、SalesForce側では顧客との関わりが薄くなり、SF側の情報はUpdateされないままとなっている。
- 社内のシステム間、データソース間で情報の差異が発生し、どの情報が最新なのかも不明な状態に陥る。

*参照元:Boomi社提供「Associate Master Data Hub」トレーニング
このような状態に陥ってしまうと、顧客に対してどの情報が正確で信頼できるのかが不明瞭になってしまい、適切なカスタマー・エクスペリエンスを提供していく際の障壁になりかねません。不正確な顧客データなどは、製品やサービスに対する信頼の喪失につながり、顧客は他の選択肢を採用してしまうかもしれません。ビジネスの損失につながる可能性があるのです。ガートナー社の調査でも企業や組織は、データ品質が低いと年間平均 1,500 万ドルの損失が発生するとされています。大変です。
MDHにはどんな特徴があるのか
マスターデータを保持するだけであれば、一般的なDBやRed HatなどのDWHサービス、AWS S3なども候補にあがるかもしれません。MDHはデータ保持に加えて、保持するデータをいかにGolden Recordsとするか、という点に対していくつかの特徴的な機能が備わっています。その中でいくつかを紹介していきたいと思います。
特徴的な機能①:MDHレコードは各データソースのレコードと一意のIDで紐付けされる。
一度MDHに取り込まれたレコードは、ソース元レコードとGRレコードを紐づけるIDが内部的に作成され、MDH内の参照テーブルに保持されます。このIDによるマッピングが今後MDHとデータソース間でデータのやり取りが発生する際に、既存レコードかどうかを判断するために不可欠なものとなります。
特徴的な機能②:IDで紐づいた各レコードは、MDHとデータソース間で常時同期できる。
IDで紐づいたレコードに対しては、各データソースでレコードがUpdateされた際に、MDHのGRをUpdateし、さらに他のデータソースに対しても最新情報をUpdateすることが可能です。各データソースに対して、MDHからUpdateするかどうかの制御も可能です。
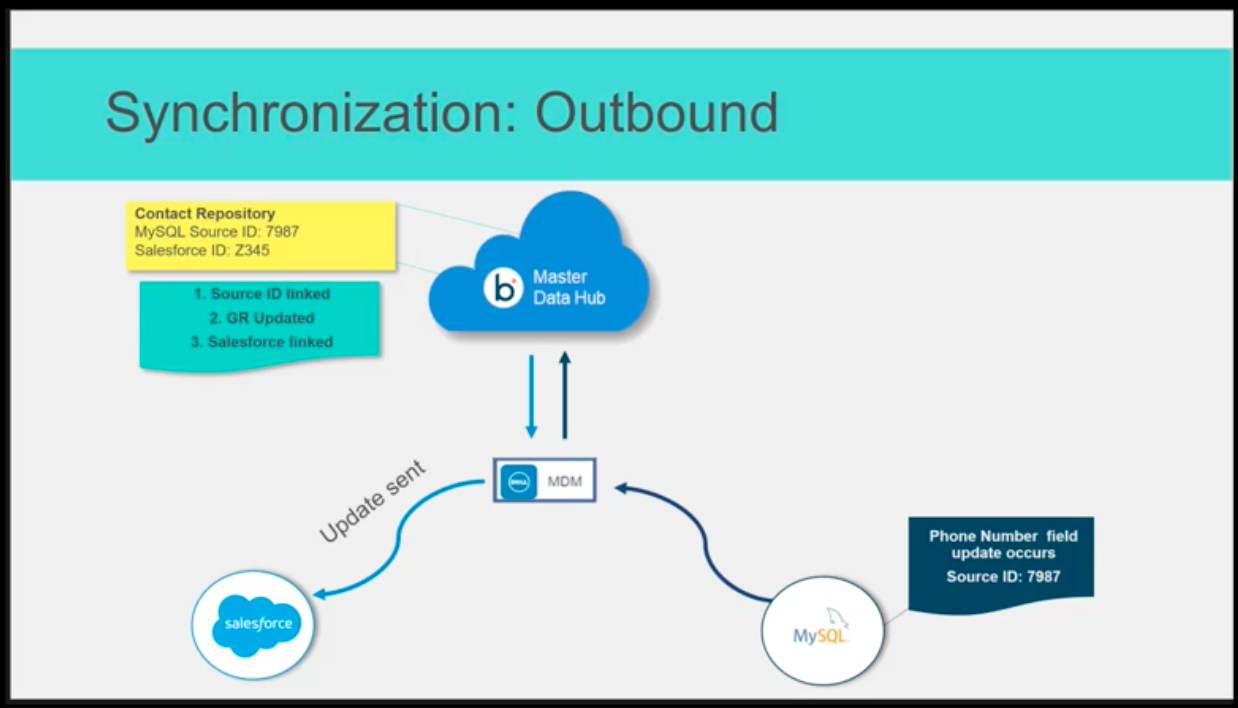
*参照元:Boomi社提供「Associate Master Data Hub」トレーニング
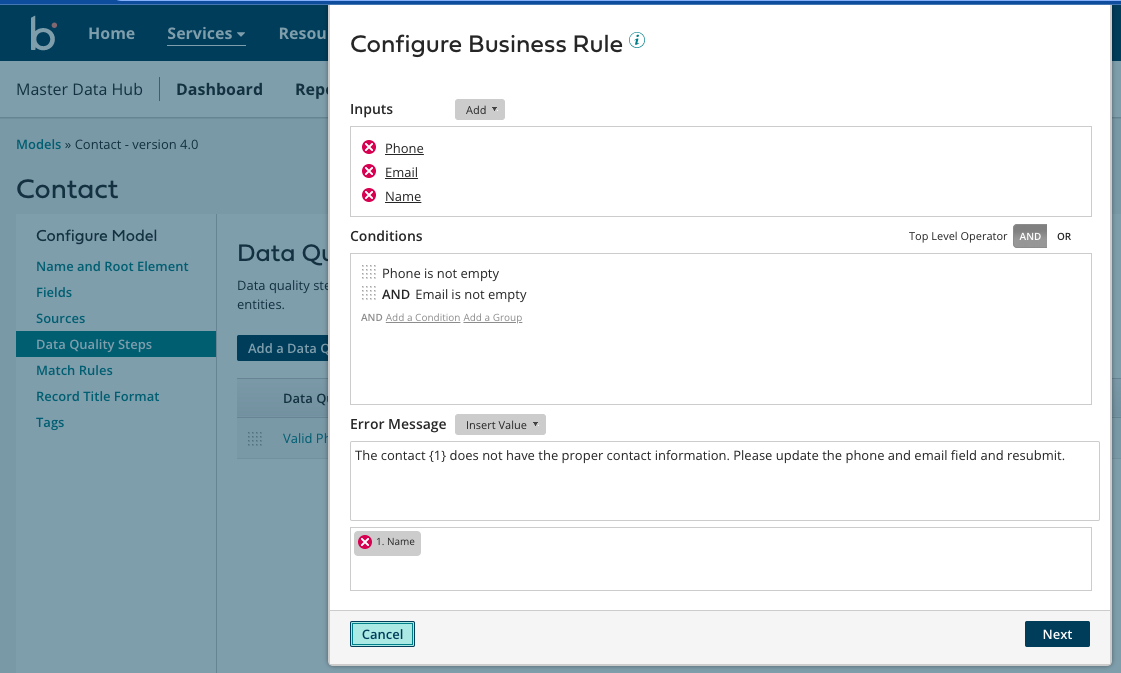
特徴的な機能③:GRを定義するModel(データオブジェクト)を作成する際に、データ精度を向上するためのルールや、重複排除するためのルールをUIを通して定義できる。
どのようなレコードをGRとして保持するかを定義する際に、MDHではまずデータのModelを作成します。そのModelを作成する際に、MDHから提供されている機能を用いて、保持するGRの精度を向上できるのです。詳細は後述の「使ってみよう」で触れたいと思います。
使ってみよう(開発)
では実際にはどのように使い始めることができるのか、MDHのLifecycleに沿って大まかに見ていきましょう。
MDHのLifecycleは Define → Deploy → Synchronize → Steward となります。
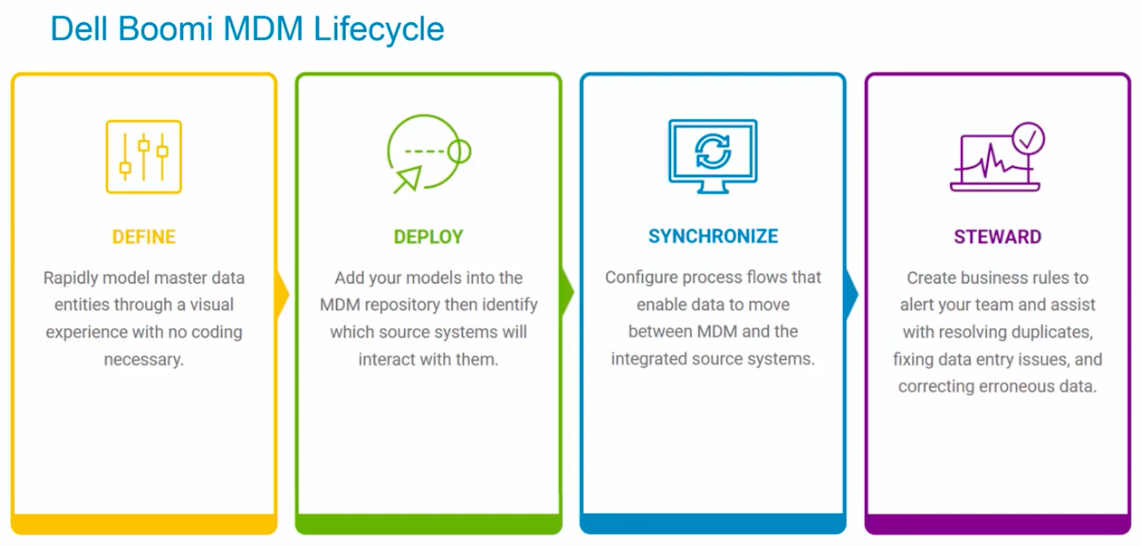
*参照元:https://www.youtube.com/watch?v=e9bKxxCf2_Q
①Define
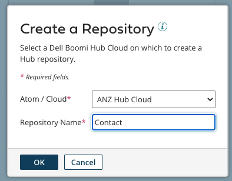
1-a. Repositoryを作成する。
Repositoryとは作成したModelが実際にホスティングされている仮想のコンテナーです。Boomiアカウント内で作成し、Atom Cloud内に保持されます
1-b. Modelの作成
MDHのUI上でGRとなるデータモデルを作成していきます。データモデルでは保持したい属性(Fields)の定義などを実施します。
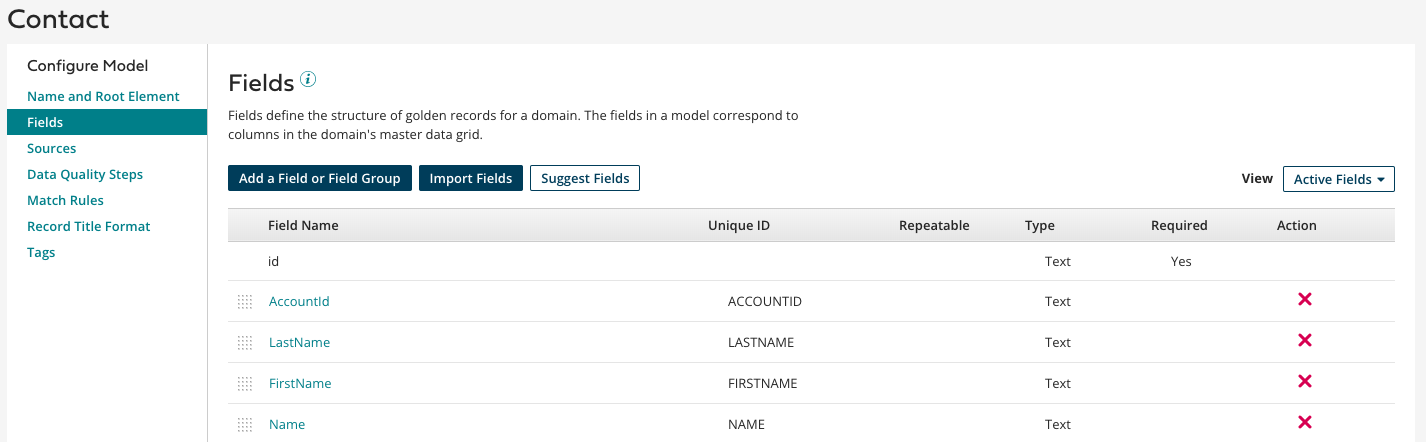
また、Modelを作成する際に上記の「特徴的な機能③」で紹介したようなGRの精度をより上げるためのルールを追加できます。以下の図では保持するデータに対して空のFieldを持つレコードを許容しないようなルールを追加しています。これらのルールもUIで簡単に定義できるのもポイントだと思いました。UIも見やすいですね。
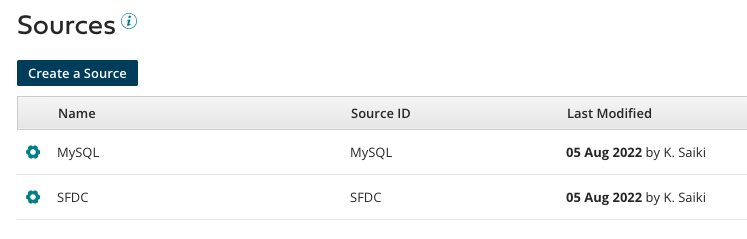
1-c. Sources(データ元ソース)の作成
MDHに接続されるデータソースを定義します。今回はMySQLとSFDCを作成しました。
②Deploy
2-a. Modelのデプロイ。
MDHでは作成したModelをRepositoryにデプロイする必要があります。デプロイ を実施しないとデータがストアされません。

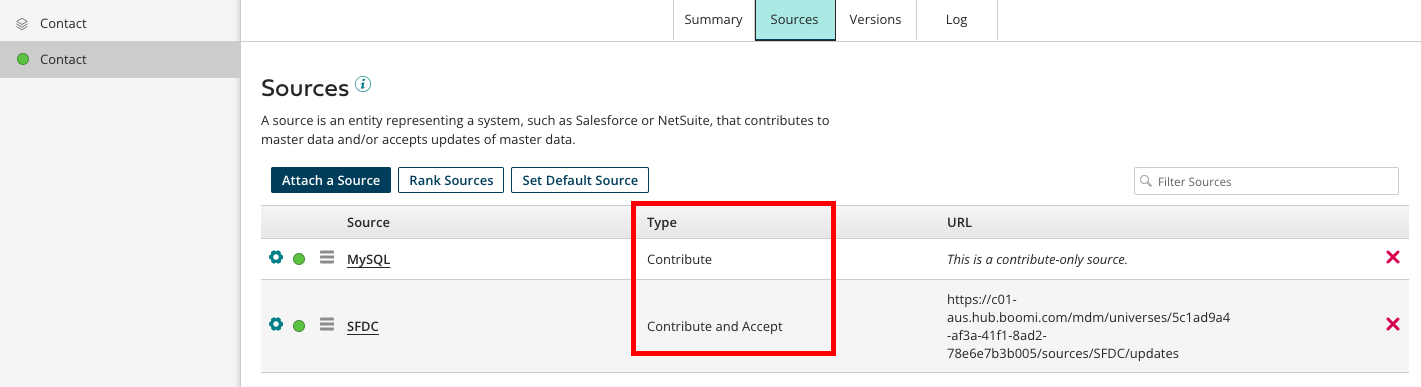
2-b. SourceのConfigurationとアタッチ
「1-c」で作成したデータソースに対して、MDHとどのような関係性を持たせるか(Type)を決めていきます。本ケースの場合は、MySQLが最新のContactデータを保持しているので、MDHに対してデータを更新する(Contribute)関係、SFDCについては、特定のFieldについてはContributeも実施し、さらにMDHから最新のContactデータを受け取るのでAcceptの役割も設定しています。
下図ではContactモデルに対してMySQLとSFDCがアタッチされている状態を示しています。
③Synchronize
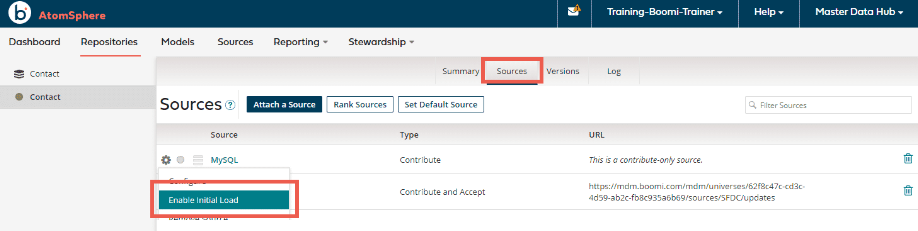
3-a. Initial Load (初回データロード)を有効化する。
各データソースとMDH間で接続チャネルを確立するために、ModelにアタッチされているSource(MySQL)に対してInitial Loadを有効化します。
3-b. データをロードする。
Source元からデータを取得しMDHにロードするには、Boomiのソリューションの一つであるIntegrationを利用します。Integrationについての詳細は以前Upしたこちらの記事を参照してください。

今回作成しているプロセスの特徴としては、MDHコネクターを利用している点です。当コネクターを利用することで、MDHに接続してデータをロードしています。
初回データロードが完了したら、Initial Loadは無効化しておきましょう。また、SFDCに対しても同様に実施します。
3-c. Real Time Integrationを作成する。
上記のようなプロセスをBoomi Atmosphereのスケジュール機能やWeb Service機能と組み合わせることで、よりリアルタイムでGRを作成/更新するような実装が可能です。
また、今回の記事ではSource⇨MDHのプロセスを例示しましたが、逆方向のMDH⇨Sourceのプロセスにも興味がある方は、こちらのBoomi Documentなども参照してみてください。
④Steward
プロセスを通してMDHに受け渡されるデータが全てGolden Recordsであるとは限りません。「1-b」で作成するようなルールに引っかかるようなレコードも出てくると思います。そんな時にデータを確認し、データの欠陥を調査したり、データ整備などを行うのがこのStewardのステップになります。
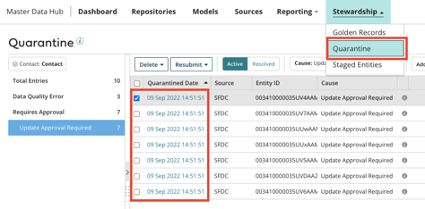
例えば以下のキャプチャだと、SFDCからロードしたデータでMDHをUpdateする際に、本当にUpdateして良いデータかどうかを「Quarantine」というメニューから確認して、結果OKだった場合はGRとしてUpdateされる、ということになります。
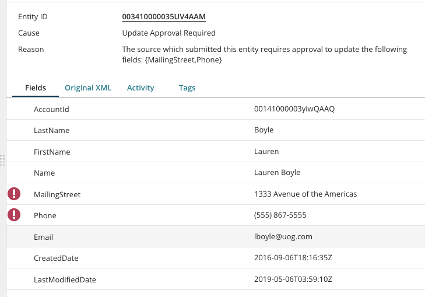
レコードの詳細を見ると、なぜ「Quarantine」に振り分けられたかの理由や、対象のFieldなども表示されており、分かりやすいですね。
実際にMDHを使ったデータインテグレーションでは、MDHへデータを更新するプロセスとStewardのステップを繰り返しながらGRを作っていく、といったイメージでしょうか。
感想と考察
今回MDHを触ってみて、従来のデータレイクやDWHでは備わっていなかったような、GR(=マスターデータ)の精度を向上する機能やデータの整備機能も利用できるのは大きなポイントかと思いました。これらの機能を基本的にUI上の開発だけで完結できるNC/LCな感じも良いですね。またBoomi Integrationとの組み合わせにより、マルチドメイン・複数システムに散らばったシステムおよびデータを統合し、組織におけるデータの一貫性とSingle Source of Truthを確立できるのは、ビズネスを推進していく上でも非常に有意だと感じました。
Go Boom it !




